
最近发现了一个绝绝子的开源项目,让我这个新手小白仅用两天时间就完成项目开发,并且功能超级完善。这效率!这成果!真心觉得这开源项目太棒了,必须得安利给大家!
项目背景
身为某不知名二流学校的研究生,意外的被导师安排个了大项目。即某海港某公司需要做一个车灯频闪检测系统,用于轮渡运输的车辆检测。轮渡运输的车辆在运输过程中,如果车灯出现频闪现象,通常意味着车辆存在电路故障或其他问题。这种故障如果不及时发现和处理,可能会导致车辆在运输过程中发生更严重的事故,甚至影响整个轮渡的安全。

原以为就是做个算法模型分析分析视频,想着我还能学一学。然而实际令我头大。虽然客户只有老掉牙的非智能摄像头,但是他既想要登录体系、管理摄像头、告警图片和视频的保存,又想要实时查看摄像头画面、实时推送到他微信等等。好家伙!既要也要呀!!干到毕业也干不完呀!!!
无可奈何只好去GitHub、淘宝、闲鱼到处搜现成的开源代码或者买已有的项目。这一调研就是两个多周,淘宝闲鱼回答能做的倒是不少,有经验的小伙伴肯定猜到了,效果没保障,不负责后续优化!!!漫天要价,动辄三五万十来万!!!你怎么不要我的命呢!!!
项目介绍
近期,我一直在为项目的推进而苦恼不已。然而,就在不久前,我意外地发现了一个开源网站,这无疑为我带来了转机。 首先 ,当然是粘贴上这宝藏项目的GitHub地址:https://github.com/AIDrive-Research/Custom-Algorithm
在该网站的助力下,我仅用两天时间便完成了项目并顺利交付,并且大部分时间其实都花在了数据集的标注工作上。此项目可满足用户训练自己专有模型,快速适配到算力设备,构建工业级智能分析产品。 整个过程仅需四步,大部分只需无脑操作即可,并且文档详细到离谱,过程也出乎意料地顺利,成果也令人惊喜。如下图,此项目让我们把重点放到专注于算法包的开发,无需考虑部署、用户如何操作等额外流程。
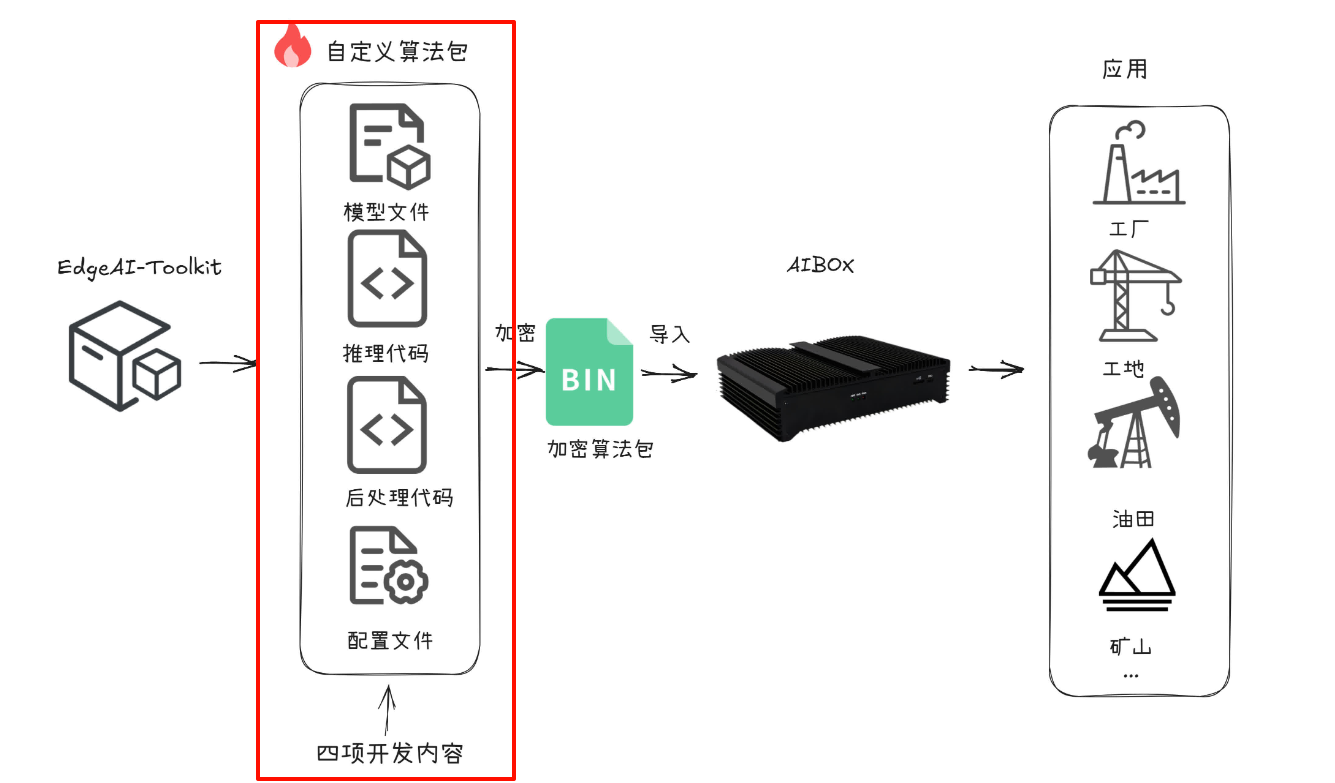
自定义算法
话不多说,直接进入快速开始。在开始之前可先把Custom-Algorithm浏览一遍。你就会发现其宛如一本武功秘籍在手,直接助你轻松速通项目,完成萌新到大佬的转变。

第一步:确定任务类型
Custom-Algorithm提供了六种案例。因为我的项目是判断车灯是否频闪,所以这里选择了目标检测类。

第二步:模型训练

标注数据集
-
下载标注工具
-
点Open Dir打开图片路径,Change Save Dir保存标注的图片数据。如下图标注车灯亮的区域。
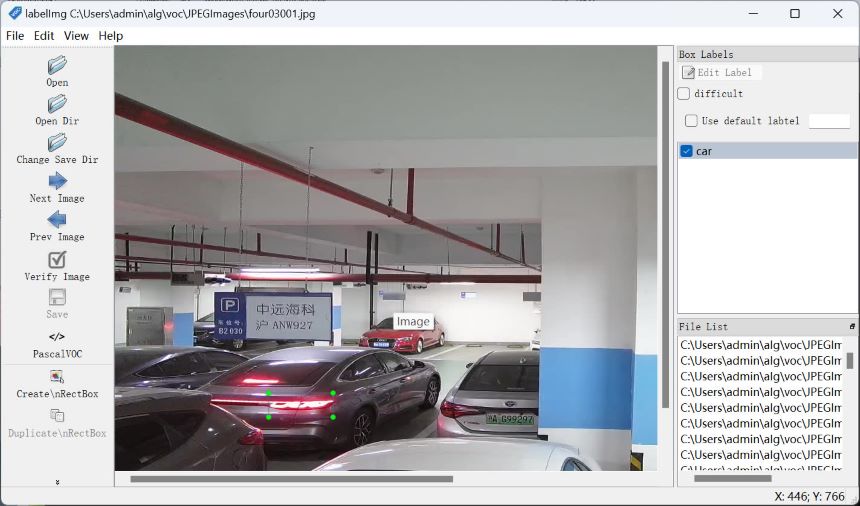
训练方法
-
环境安装,这里推荐使用MiniConda创建独立的虚拟环境
conda create -n py310-alg python=3.8 # 新建python环境 git clone https://github.com/AIDrive-Research/EdgeAI-Toolkit.git # 下载项目 cd EdgeAI-Toolkit/train/detection/yolov5 # 切换目录 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ # 安装依赖 -
数据准备
使用标注工具制作VOC格式数据集如下格式
JPEGImages: xxx.jpg Annotations: xxx.xml -
将VOC格式数据集转成YOLO格式
修改tools/0_xml2txt.py
CLASSES = ['car'] # 目标类别 XML_DIR = '/data8/user/xxx/alg/voc/Annotations' # VOC标注文件路径 JPEG_DIR = '/data8/user/xxx/alg/voc/JPEGImages' # 图片文件路径 LABEL_DIR = '/data8/user/xxx/alg/voc/labels' # YOLO格式标注文件存储路径并执行
python tools/0_xml2txt.py -
拆分训练集和验证集
python tools/1_split_train_val.py --input-images /data8/user/xxx/alg/voc/JPEGImages --input-labels /data8/user/xxx/alg/voc/labels --output /data8/user/xxx/alg/voc/yoloout -
编写yaml文件
path: /data8/user/fudaocheng/alg/voc/yoloout # YOLO数据集存储路径 train: images/train val: images/val test: nc: 1 # 类别数目 names: ['car'] # 类别名称,与CLASSES相同 -
训练以及导出
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data data/custom.yaml --weights yolov5s.pt --device 0,1 # 多卡训练 python export_rk.py --weights xxx.pt --include onnx --simplify --opset 12 --rknpu rk3588 # 导出模型
模型量化
-
下载模型量化
-
环境安装
cd rknn-toolkit2 conda create -n py38-rk2.2 python=3.8 # 创建虚拟环境 conda activate py38-rk2.2 #激活环境 pip3 install rknn_toolkit2-2.2.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl -
量化准备
在训练集中随机选取图片进行模型量化,数量在80-120之间。
执行
find ./images/ -name "*.jpg">custom.txt,目录结构如下
-
模型量化
修改convert.py的DATASET_PATH为量化图片的路径,并执行:
python convert.py /data8/user/xxx/alg/EdgeAI-Toolkit/train/detection/yolov5/runs/train/exp10/weights/best.onnx rk3588 i8 /data8/user/fudaocheng/alg/out_rknn/best_model.rknn
通过上述步骤即可把onnx模型量化为rknn格式。(注:如果失败,多数是因为numpy版本不对)
第三步:编写推理代码或后处理代码
因为开发样例包括了大部分的场景。同样车灯频闪也属于其中,并且属于简单的检测目标检测类,所以我这里不需要编写推理代码和后处理代码。你敢信,无脑操作模型训练、量化后,万里长征就要走完了!!!
第四步:算法包配置和加密
根据对应类别选择已有的开发样例,根据文档在其基础上修改算法包名称等配置项。改不全也问题不大,后期还是可以改的。

改完之后,直接使用提供的加密工具进行加密即可(注:加密路径填写加密算法包的上级路径)
最后最后,激动人心的时刻到了,输入ip+9092端口进入盒子管理后台,点击算法仓库-算法导入。把加密后的bin文件上传。
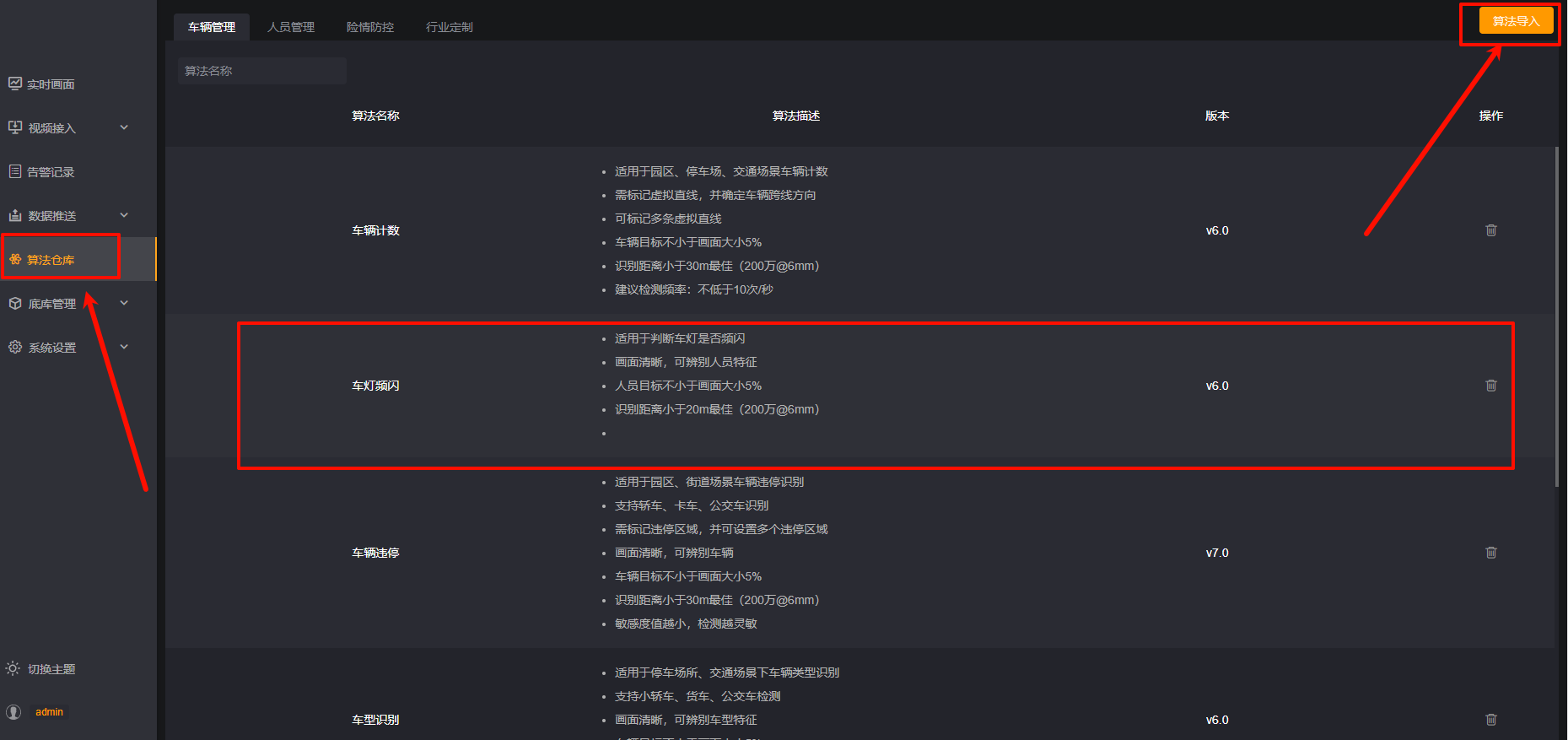
选择视频接入-摄像头进行添加摄像头,算法选择车灯频闪,如下图:
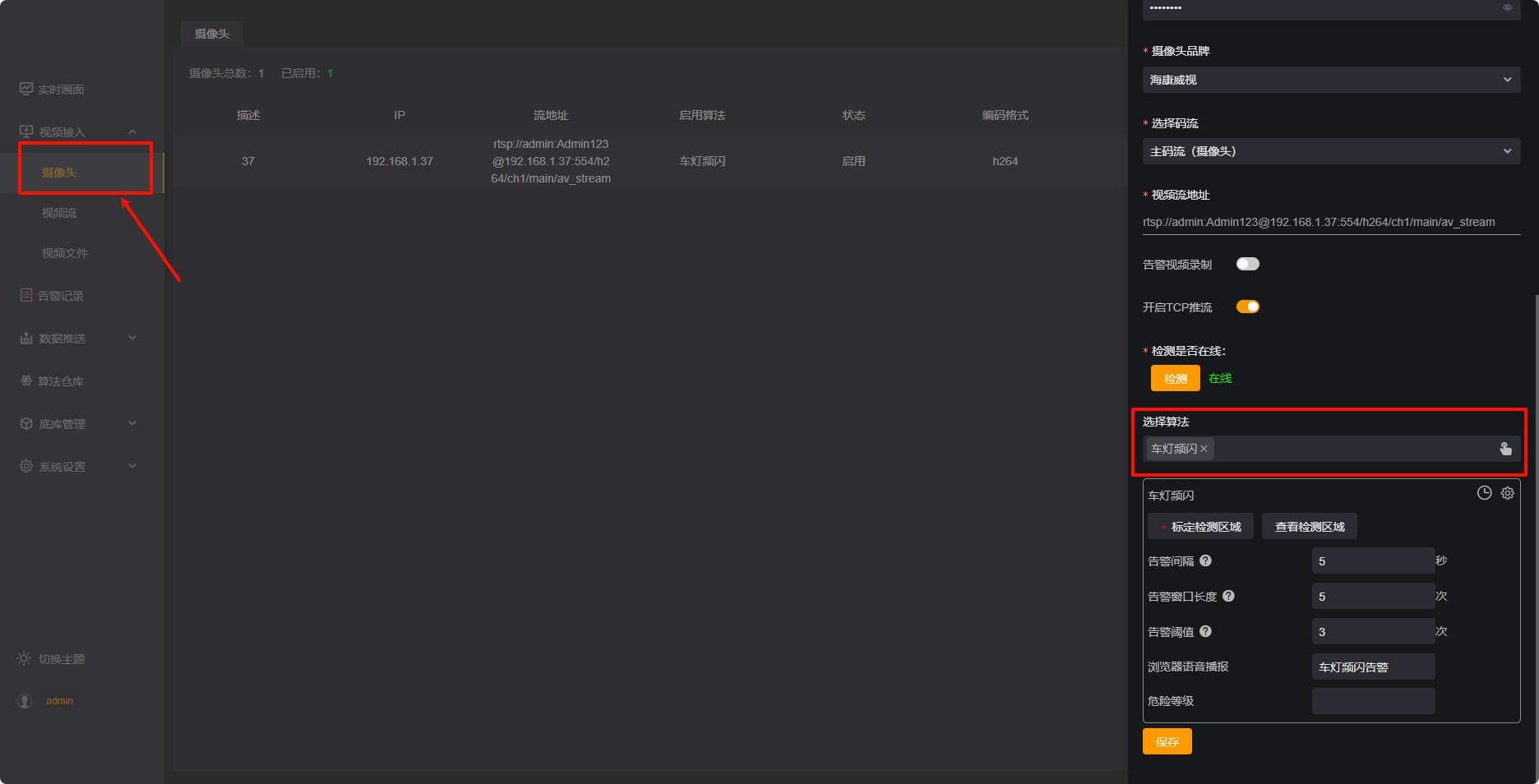
打开告警记录。哦豁,成功了!!!产生告警了!!!如下图告警记录:

成果展示
成果当然是我很爽,老师很开心,客户超级满意喽。哈哈哈哈,虽然误报率还有些高,后期还需要根据实际的情况加大样本进行优化。但是本该小半年的项目交付时间竟不到一个周就完成了!!!并且功能齐全,简单易上手,爱了爱了。
回复