
一、简介
现阶段,利旧摄像头通过内置于智能分析盒内的小模型算法进行AI分析。小模型算法在推理速度上明显,但是由于参数量少,语义理解能力不足,所造成的后果是复杂场景误报多,精准度不足。大量的误报给人工处理增加了负担。
因此,如何提高模型在不同场景下的识别精度是亟待解决的问题。大模型的出现给视频场景理解与分析带来了全新视角,其独特的语义理解能力与指令化交互方式可应对复杂场景复杂业务逻辑下的精准识别。为此,采用多模态大模型对小模型识别结果进行二次复判,可弥补小识别精度不足的问题。
本文将重点关注以下三个方面内容:
1、多模态大模型是什么?2、多模态大模型技术原理是什么?3、多模态大模型在安全生产领域如何应用?
二、多模态大模型是什么?
2022年底,由OpenAI发布的ChatGPT大语言模型,引起了业界广泛关注。在大数据、大模型、大算力加持下,其语义理解与生成能力得到“涌现”。不同于大语言模型,多模态大模型能够同时处理文本、图像、音视频数据,并生成多模态数据。那多模态大模型到底是什么?核心技术有哪些?能够产生什么样的应用价值?
多模态大模型全称Multi-modal Large Language Model,简称MLLM。该模型能够做什么?其按照类型可分为任务理解型与任务生成型两类多模态大模型。
1、任务理解型多模态大模型
顾名思义,该类大模型是为理解多模态内容而设计。大模型输入为文本指令与图像、音视频内容,输出为对图像、音视频内容的指令理解。其核心为利用大模型丰富的通识知识与垂域知识,对多模态内容深度语义理解与生成。该应用在安全生产监控中具备应用价值,比如,给大模型输入一张监控图像,并提供一段提示词,让大模型输出场景中是否存在异常行为。再比如,该大模型一段音视频与提示词,让大模型决策是否存在暴力行为。
2、任务生成型多模态大模型
该类大模型以任务生成为驱动进行设计。大模型的输入为文本指令与图像、音视频内容,输出为指令下的图像、音视频。有什么应用呢?图像生成与视频生成是典型应用。比如在绘画创作、影视制作中,给定一段提示词,生成一张高保真绘画或一段逼真视频。前段时间爆火的sora亦属于任务生成型的多模态大模型。
三、多模态大模型技术有哪些?
本文重点关注任务理解型的视频分析多模态大模型。以下为多模态大模型的主流技术架构与训练方法。

1、技术架构
下面列出几个典型的多模态大模型。
| 名称 | 时间&单位 | 能力 |
|---|---|---|
| GPT-4V | 2023年9月&OpenAI | 理解任务(图像描述、视觉推理、目标定位) 生成任务(图像生成) |
| LLaVA-1.5 | 2023年10月&威斯康星麦迪逊分校&微软 | 理解任务(图像描述、视觉推理) |
| CogVLM | 2023年10月&清华大学 | 理解任务(图像描述、视觉推理、目标定位) |
| Qwen-VL-Max | 2024年1月&阿里巴巴 | 理解任务(图像描述、视觉推理) |
典型的多模态大模型架构分为模态编码器、预训练大语言模型、模态转换器三部分。做一个类比,模态编码器如人类的眼睛/耳朵,将图像、声音信息进行编码得到可处理的信号;预训练大语言模型相当于人类大脑,负责理解处理这些信号,并作出决策;模态转换器作为中间桥梁,对齐多模态编码信号与文本信号,因为大语言模型的输入为文本编码,不理解其他模态编码,因此,需要模态转换器作为翻译,将其他模态编码转换为文本编码。
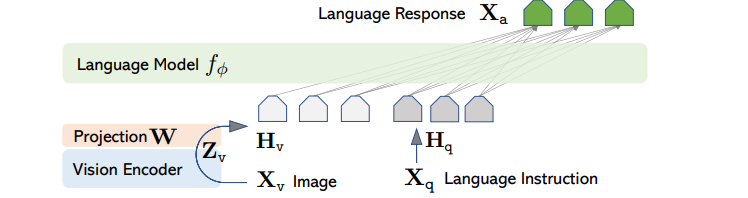
1.1 模态编码器 模态编码器负责将图像、音视频多模态原始数据编码成可处理的向量形式,其过程特征提取与压缩。典型的模型编码器如下。
- CLIP
2021年美国OpenAI公司发布了跨模态预训练大模型CLIP,其设计目的主要用作图文检索。该模型采用从互联网收集的4亿对图文对。采用双塔模型与比对学习训练方式进行训练。CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。
简单的说,CLIP将图片与图片描述一起训练,达到的目的:给定一句文本,匹配到与文本内容相符的图片;给定一张图片,匹配到与图片相符的文本。因此,其学习到的特征是图片-文本具有一致性的特征。模态编码器采用其视觉编码器对图像数据进行编码。
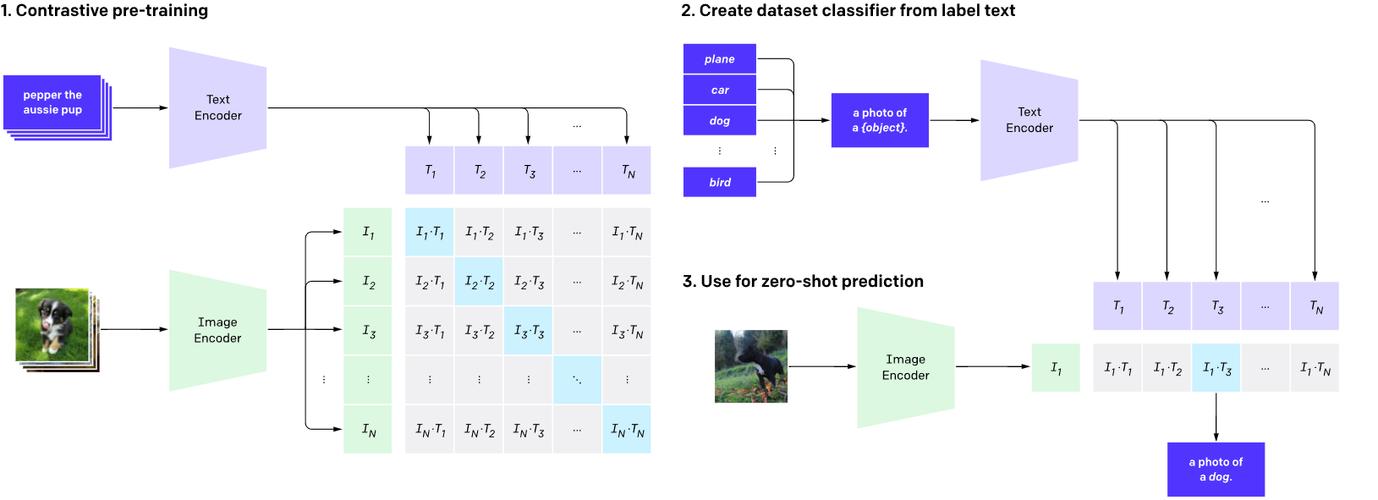
如上图,文本原始数据经过文本编码器、图像原始数据经过图像编码器,分别得到相应向量。基于文本-图像匹配对以及对比学习进行训练,如果文本-图像匹配,其损失值小;相反,其损失值增大。通过这种对比学习,使语义相同的文本图像对向量靠近,相反,拉远向量距离。这样,训练完成的文本-图像编码器可以提取用于比对的一致性特征。其主要提取的特征主要用于跨模态检索,如以文搜图。
- BLIP
2022年美国salesforce公司发布了跨模态预训练大模型BLIP。其主要解决CLIP的两方面问题:第一,噪声数据多,模型特征存在偏差;第二,编码器结构,难以生成图像描述。BLIP采用了编码器-解码器架构与过滤器数据增强提升数据质量。
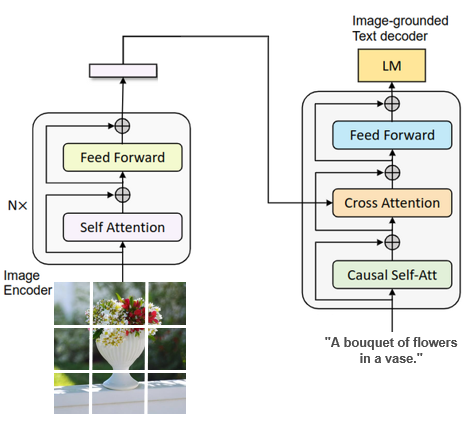
CLIP主要为图文检索而设计。也就是说给定一张图片,从候选文本列表中选出最符合的那个文本,其无法基于图像直接生成文本。如上图,BLIP的编码器-解码器的网络架构,允许模型基于给定图片,生成相应描述。此外,其设计了CapFilt的过滤器,评估图像-文本之间的匹配程度,如果不匹配,则过滤掉噪声图文对,并结合人工标注数据,生成高质量多模态模型。
1.2 预训练大模型
无需从头训练大模型,目前开源界提供了众多优秀大语言模型。按照架构可分为编码器-解码器架构、因果解码器架构以及混合专家模型架构。
下面列出几个典型的大语言模型。
| 名称 | 时间&单位 | 参数量 | 架构 |
|---|---|---|---|
| Flan-T5 | 2022年10月&Google | 3B/11B | encoder-decoder(编码器-解码器) |
| LLaMA | 2023年2月&Meta | 7B/13B/33B/65B | causal decoder(因果解码器) |
| Vicuna | 2023年3月&UC Berkeley | 7B/13B/33B | causal decoder(因果解码器) |
| Qwen | 2023年9月&阿里巴巴 | 2B/7B/70B | causal decoder(因果解码器) |
| Deepseek | 2024年12月&深度求索 | 671B | mixture of experts(混合专家模型) |
编码器-解码器与因果解码器架构有什么区别?
(1)编码器-解码器:适用于有明确输入-输出关系的任务。如机器翻译、文本摘要、情感分类等。
(2)因果解码器:适用于自回归生成任务,如文本生成、代码生成等。
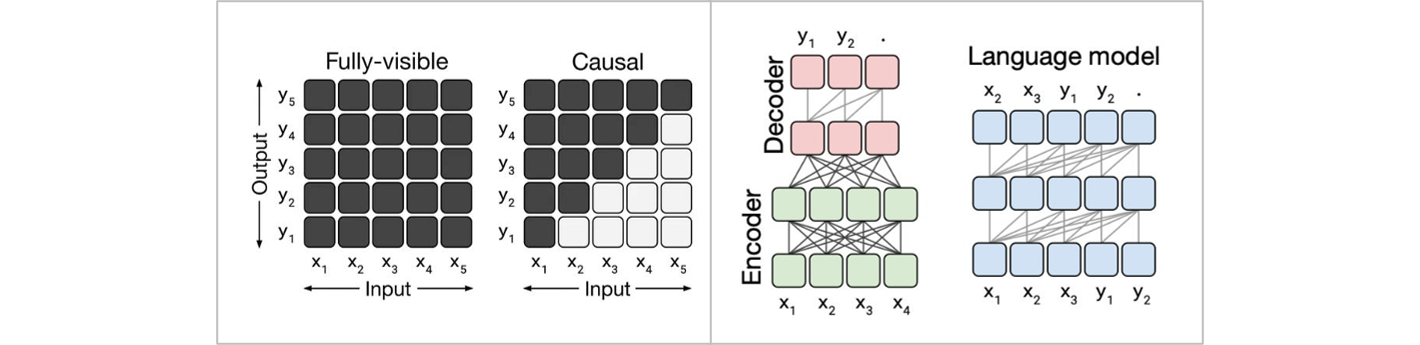
如上图,对于编码器-解码器架构fully-visible,每一个输出都会基于所有的输入决策;而对于因果解码器,每一个输出会基于之前的输入决策。举个例子:比如将“I love machine learning”翻译成中文为“我喜欢机器学习”。对于编码器-解码器架构需基于“I love machine learning”全部内容以及已生成的内容输出当前内容,而对于因果解码器架构,如预测“学习”,则基于“机器”或一定窗口的先前数据预测当前内容。
- 编码器-解码器
Flan-T5为谷歌在2022年提出的序列到序列文本生成模型。模型采用transformer架构用于机器翻译、文本摘要、情感分类等多种任务。
编码阶段: 输入序列经分词器进行tokenization,每个token进行向量化,得到N * 768的特征向量,其中N为token的个数,768为每个token的维度。特征向量送入Transformer block,经过多头注意力机制,输出 N * 768的隐藏层特征向量。该特征向量供解码器解码调用。
解码阶段: 分词与向量化步骤与编码阶段完全相同。与编码阶段不同的是,解码阶段使用mask多头注意力机制,也就是在计算注意力时,只考虑已经预测出的向量。解码多头注意力输出与编码器输出,再次进行多头注意力融合,解码得到最终输出。
编解码器交互: 解码器输出时,中间层与编码器输出进行多头注意力加权,这样做的目的是,让解码器选择性关注解码器不同部分的输出。

- 因果解码器
GPT, LLaMA是因果解码器架构的典型代表,即属于decoder only架构。为什么是decoder only? 该类模型的主要任务是文本生成。语言生成的本质是逐字逐句的往下写或往下说,每一步都基于之前生成的内容进行表达,没必要每一步都去看一下输入的问题是什么。因此,没必要采用编码器,去掉编码器也使得计算复杂度更低,网络结构更加简洁。
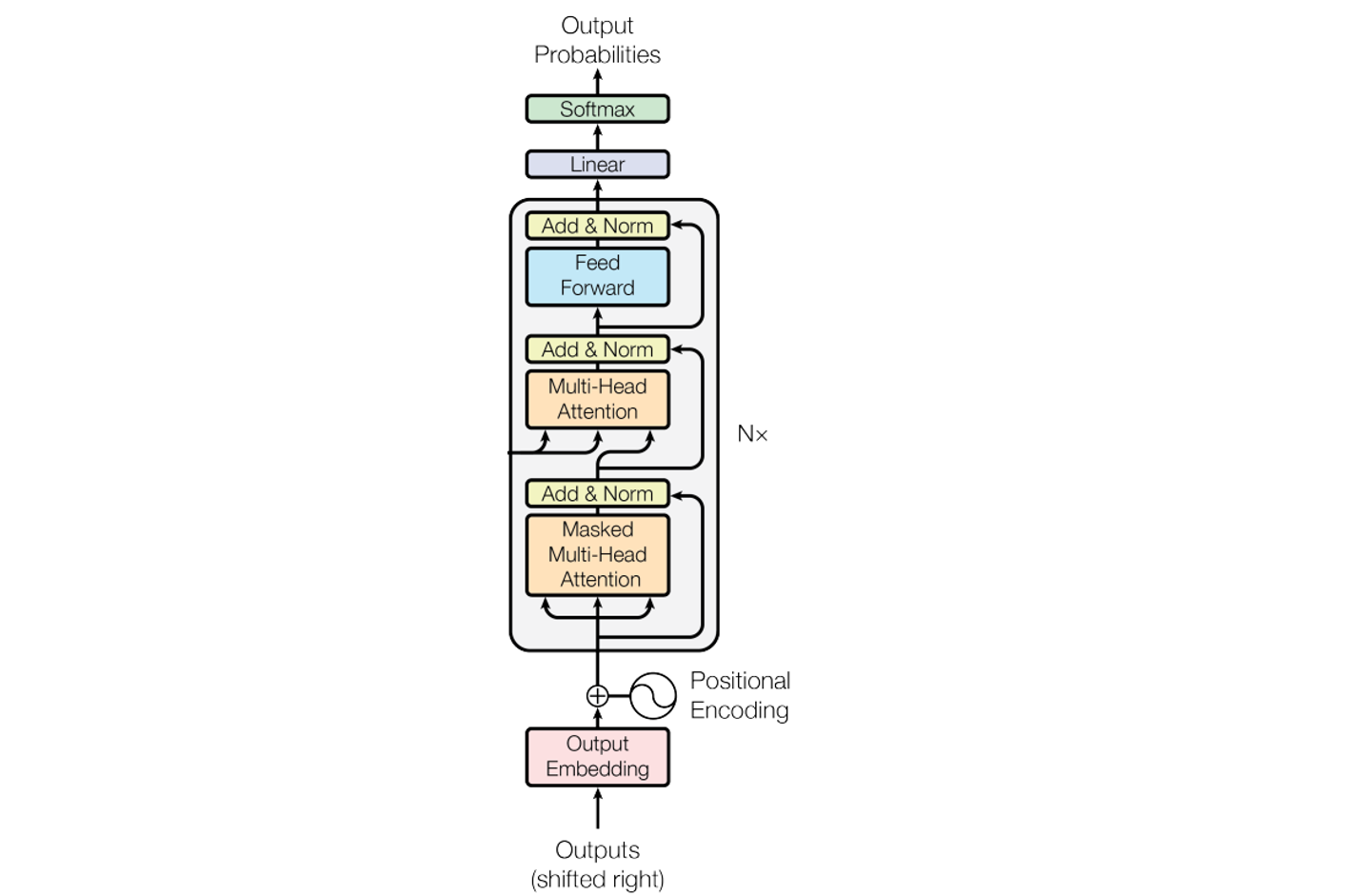
上图可以看出,decoder only架构只保留了解码器部分。基于已生成的序列,逐步生成完整序列。
- 混合专家模型(MoE)
近期,国产大模型引deepseek起了人们广泛关注,其采用MoE网络结构设计,从而使其保持低成本的训练与推理。MoE的提出主要是解决大参数量模型训练推理资源耗费大的问题。比如,GPT-3的网络参数为1750亿,如果训练或推理时,这些参数全部激活会导致效率降低。能不能根据输入只激活最相关的一部分?比如处理英文任务时,激活英文相关的模块,处理中文任务时,激活中文相关的模块。MoE将模型分为多个“专家”子网络,每次只让部分专家参与处理,其余部分保持不变。

如上图,每个输入实例,门控网络会选择少量“专家”系统参与处理,其余部分保持不活跃。这种稀疏性与选择性是门控网络针对每个实例动态实现的,具备灵活性。
1.3 模态转换器
大语言模型只能处理文本数据。如何处理其他模态数据?一种方法是从头训练一个编码器,使输入图像直接转换至LLM输入特征。这种方式训练成本高。正如前面所述,我们已具备模态编码器预训练模型,只需开发一个模态转换器将图像特征翻译成文本特征即可。这个模态转换器可以是MLP或其他神经网络。这样只需训练少量对齐参数,即可实现不同模态特征对齐。
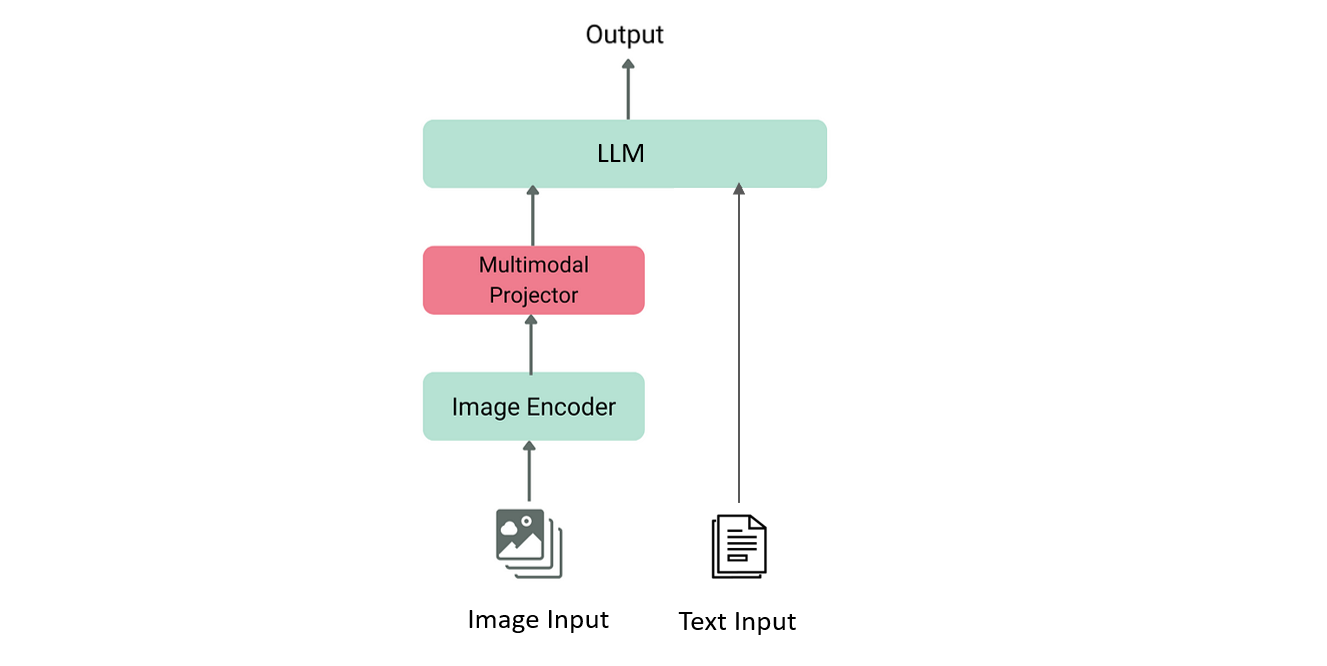
如上图,红色部分为模态转换器,其将图像编码器的输出映射至文本空间,与输入文本一起作为LLM输入。
2、训练方法
多模态大模型的预训练、指令微调、对齐微调到底有什么区别?如何对这三部分进行训练?
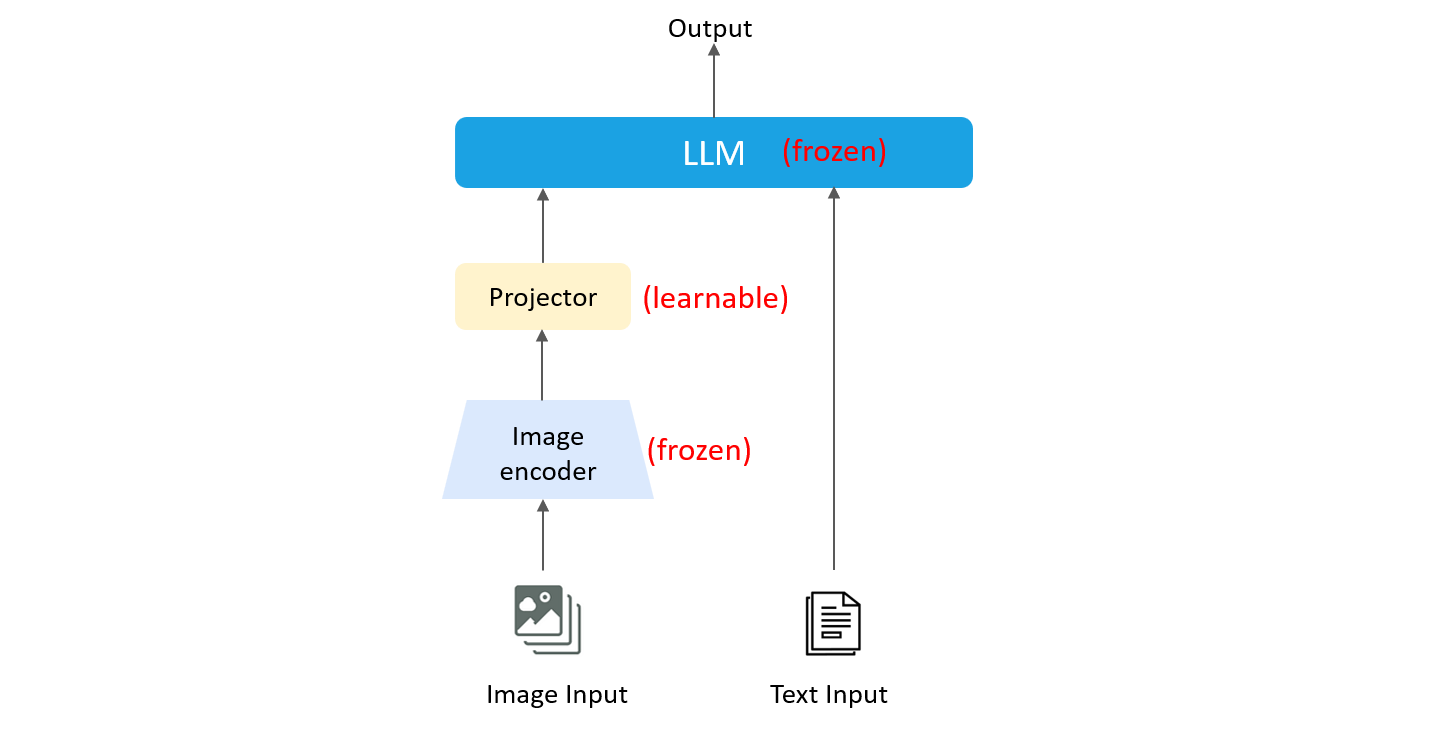
- 预训练(pre-training)
预训练阶段目的是对齐不同模态特征,学习模态通识知识。因此,其训练的部分为模态转换器,即下图中的Projector。在训练期间,图片编码器&LLM权重处于冻结状态。预训练阶段有哪些开源数据集?格式是什么样的?
下表为典型预训练数据集。
| 数据集 | 样本数 | 发布时间 |
|---|---|---|
| CC-3M | 3.3M | 2018 |
| CC-12M | 12.4M | 2020 |
| LAION-COCO | 600M | 2022 |
| LAION-700M | 747M | 2022 |
| ShareGPT4V-PT | 1.2M | 2023 |
数据集格式简单示例如下:
{
"annotations": [
{
"image_url": "https://example.com/image1.jpg",
"caption": "A cat sitting on a couch."
},
{
"image_url": "https://example.com/image2.jpg",
"caption": "A red car parked by the road."
}
]
}
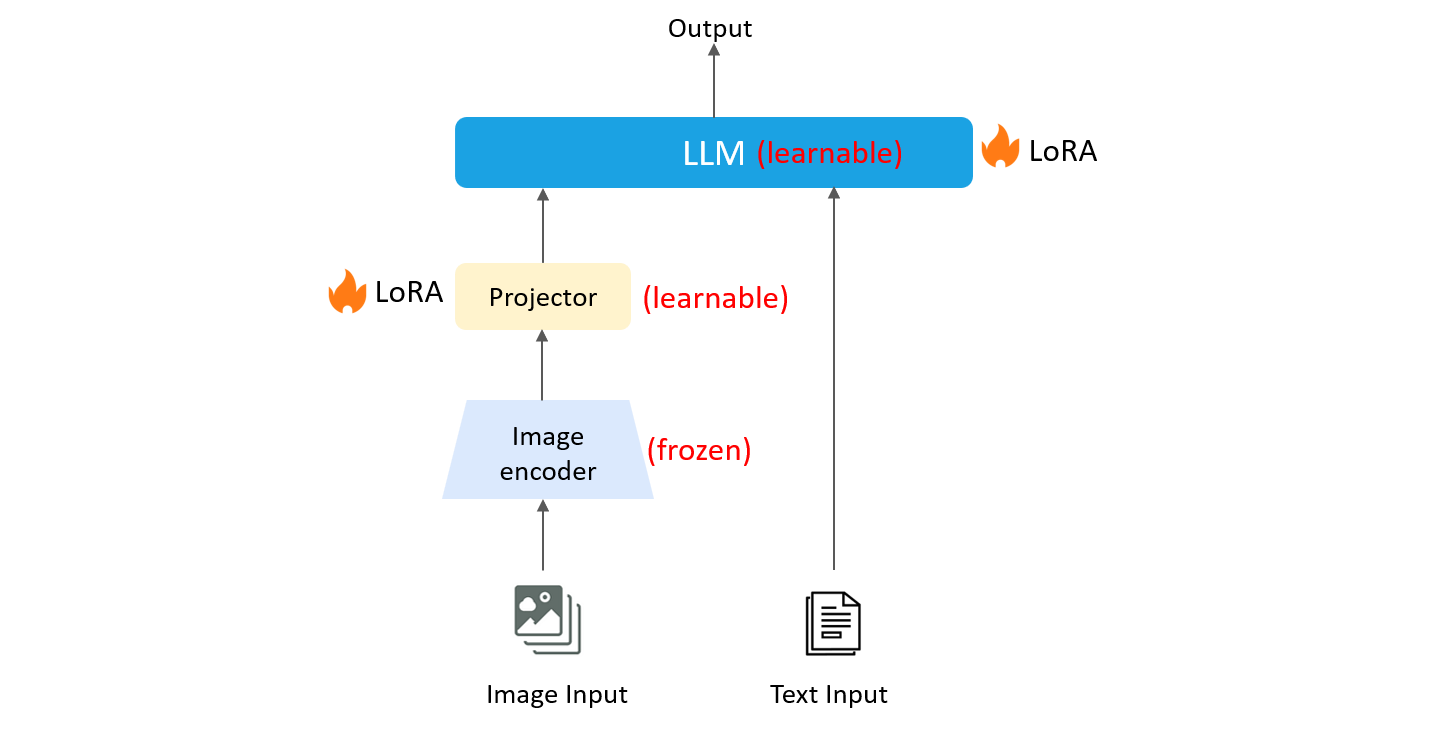
- 指令微调(instruct-tuning)
多模态大模型预训练模型更多的是学习通识知识。指令微调的目的是让大模型更好的学习特定领域知识,完成特定任务。训练期间,图像编码器权重冻结,模态转换器与LLM权重,通过LoRA高效微调,指令微调有哪些数据集?格式是什么样的?
下表为典型指令微调数据集。
| 数据集 | 样本数 | 模态 |
|---|---|---|
| LLaVA-Instruct | 158K | 图像+文本->文本 |
| LVIS-Instruct | 220K | 图像+文本->文本 |
| ALLaVA | 1.4M | 图像+文本->文本 |
数据集格式简单示例如下:
{
"id": "000000215677",
"image": "000000215677.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\nWhat skill set might someone need to perform such a frisbee trick?"
},
{
"from": "gpt",
"value": "To perform the frisbee trick shown in the image, where the man is passing a frisbee between or underneath his legs, a person would need a combination of skills."
}
]
}
- 对齐微调(alignment tuning)
对齐微调的目的是使大模型的输出与人类偏好对齐。也就是使模型的输出结果更符合人类价值观。基于人类反馈的强化学习RLHF是对齐微调的主要方法。如何进行对齐微调?
RLHF对齐微调方法主要分为两步:
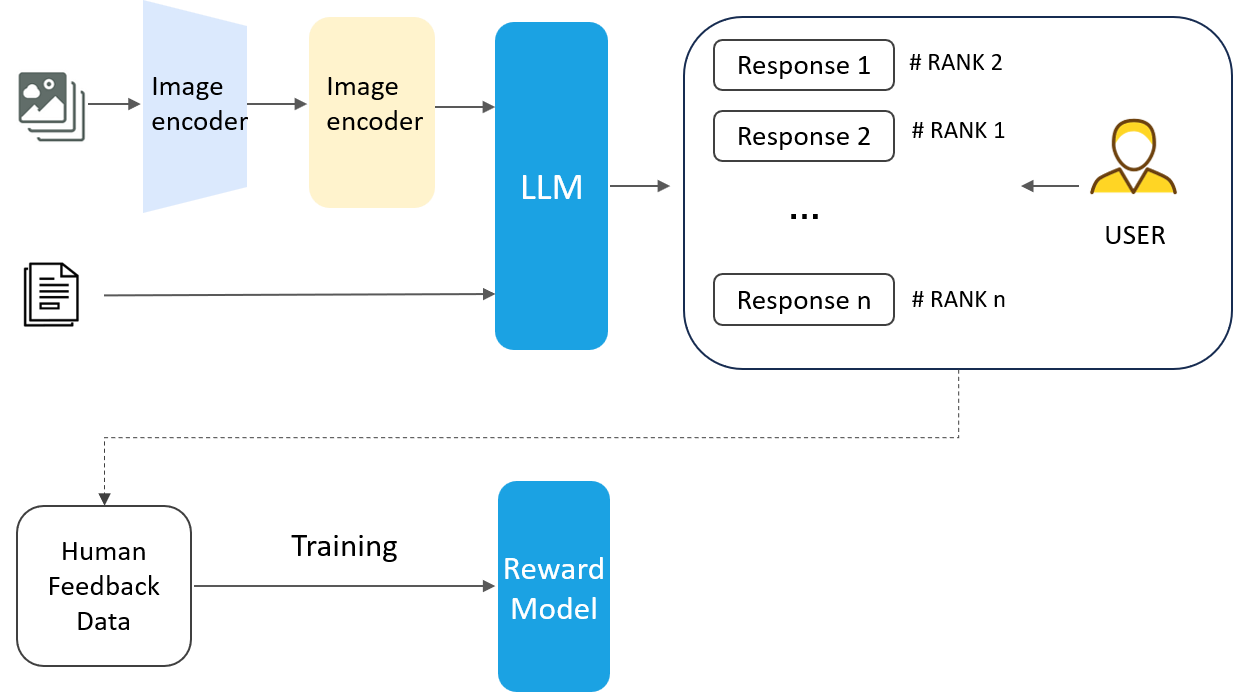
第一步: 训练RM奖励模型。如下图,多模态大模型基于同一问题,生成多次答案,由人工对这些答案按照质量进行排序。从人工反馈中构建监督数据集,并训练奖励模型,对多模态大模型的生成结果进行评估。
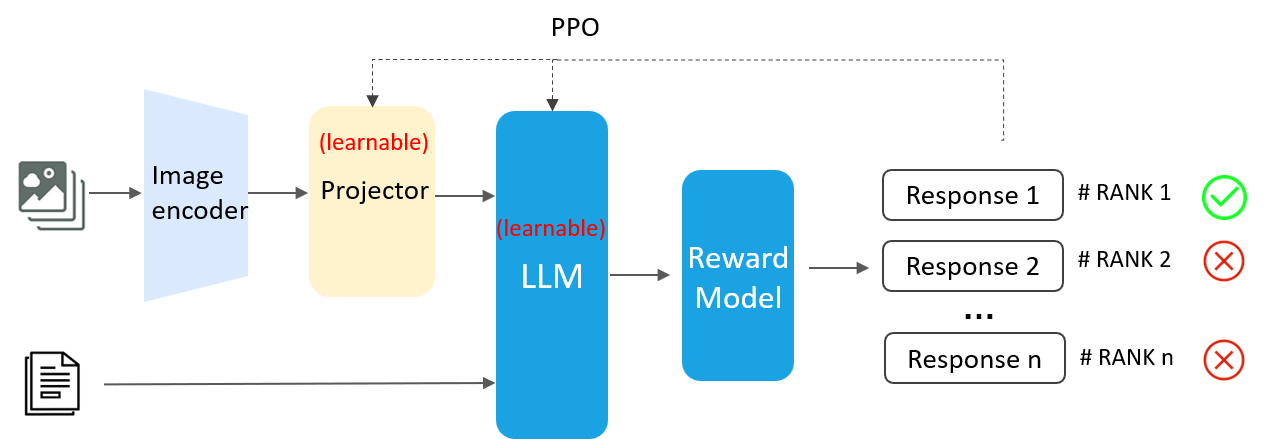
第二步: PPO算法更新网络权重。如下图,在对齐微调中,模态转化器与LLM权重为可学习状态。准备问题数据集,基于同一问题的不同回答进行评分,同时,更新模型权重。微调的最终目的是,使模型对同一问题的多次回答,符合人类期望。
四、多模态大模型安全生产如何应用?
多模态在安全生产视频分析监测的主要应用方式为:二次复判。大小模型联动是可行方案。原因是,只采用小模型难以应对复杂场景误报问题;只采用大模型,难以承担实时分析的高算力资源问题。产品详情如下。
1、部署组网
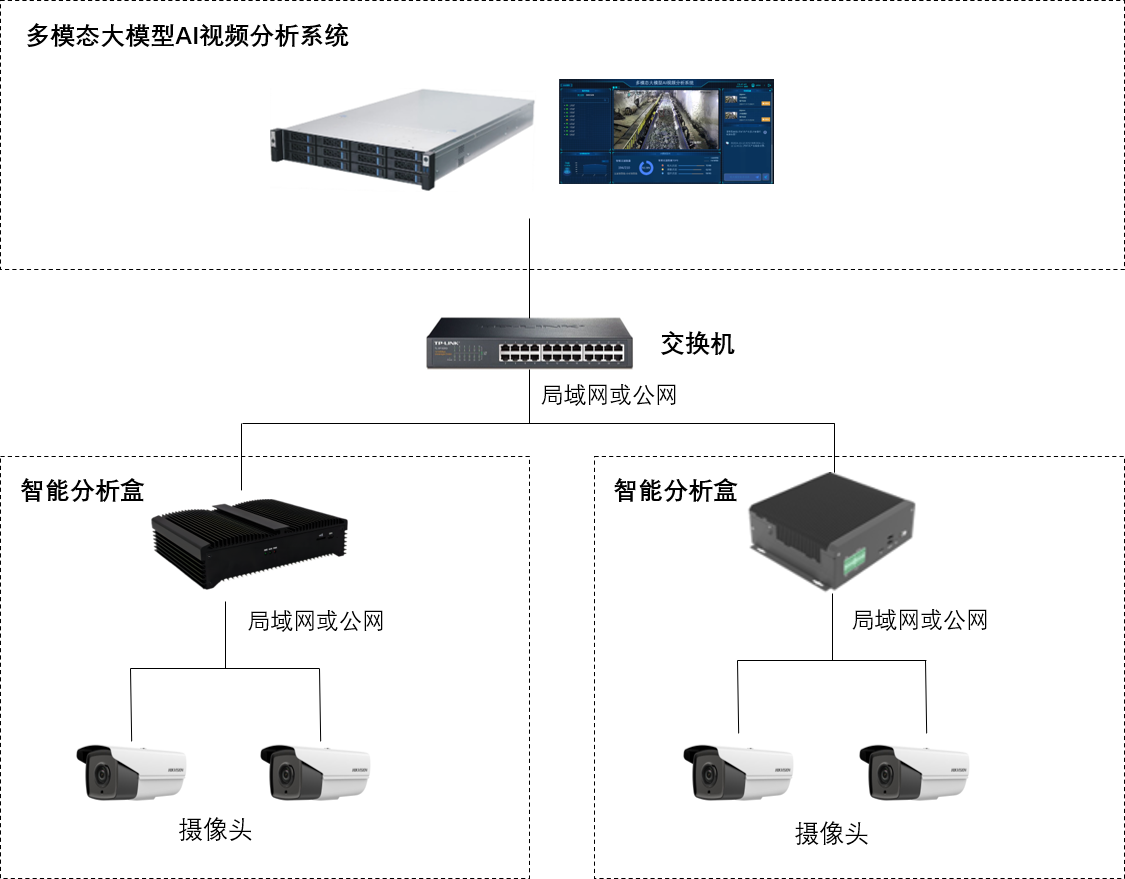
如上图,网络摄像头经局域网或公网接入智能分析盒。盒子内置AI小模型算法,产生的告警通过局域网或公网,进入多模态大模型AI视频分析系统。系统内置多模态大模型,基于自定义的复审提示词,对小模型告警数据进行二次复审。
2、设备配置
| 项目 | 指标 | |
| 基础配置 |
CPU:Intel Xeon 6230 20核心*2 GPU:RTX3090*2 内存:64GB 硬盘:1TB SSD+8TB HDD 尺寸:2U机架式服务器 |
|
| 模型 | MLLM-2B | MLLM-7B |
| 最大输入token | 2048 | 2048 |
| 最大输出token | 512 | 512 |
| 推理速度 | 1秒1帧 | 2秒1帧 |
3、技术指标
| 项目 | 子项 | 小模型 | 大模型 | 备注 |
| 平均准确率 | 标准场景 | 95.2% | 99.8% | 如未佩戴安全帽检测 |
| 非标场景 | 62.3% | 89.6% | 如叉车货物超高检测 | |
| 场景准确率 | 人员复杂行为 | 43.2% | 85.2% | 如打架检测 |
| 人机交互行为 | 52.3% | 88.3% | 如人员倚靠货物检测 | |
| 复杂事件逻辑 | 63.5% | 89.4% | 如验电作业未穿工服 | |
| 复杂语义行为 | 73.8% | 91.6% | 如灯光场景明火检测 |
4、使用方法

使用流程如上所示。分为盒子端与平台端操作两部分。
-
盒子端操作: 告警推送地址配置。在盒子端填写平台推送地址,将告警推送至大模型平台。
-
平台端操作: 首先在交互模式中测试提示词是否有效。如果有效,创建复审任务,填写任务名称与提示词。在任务查看中,可查看复审任务,在复审结果中可查看大模型的审核结果。
具体方法如下。
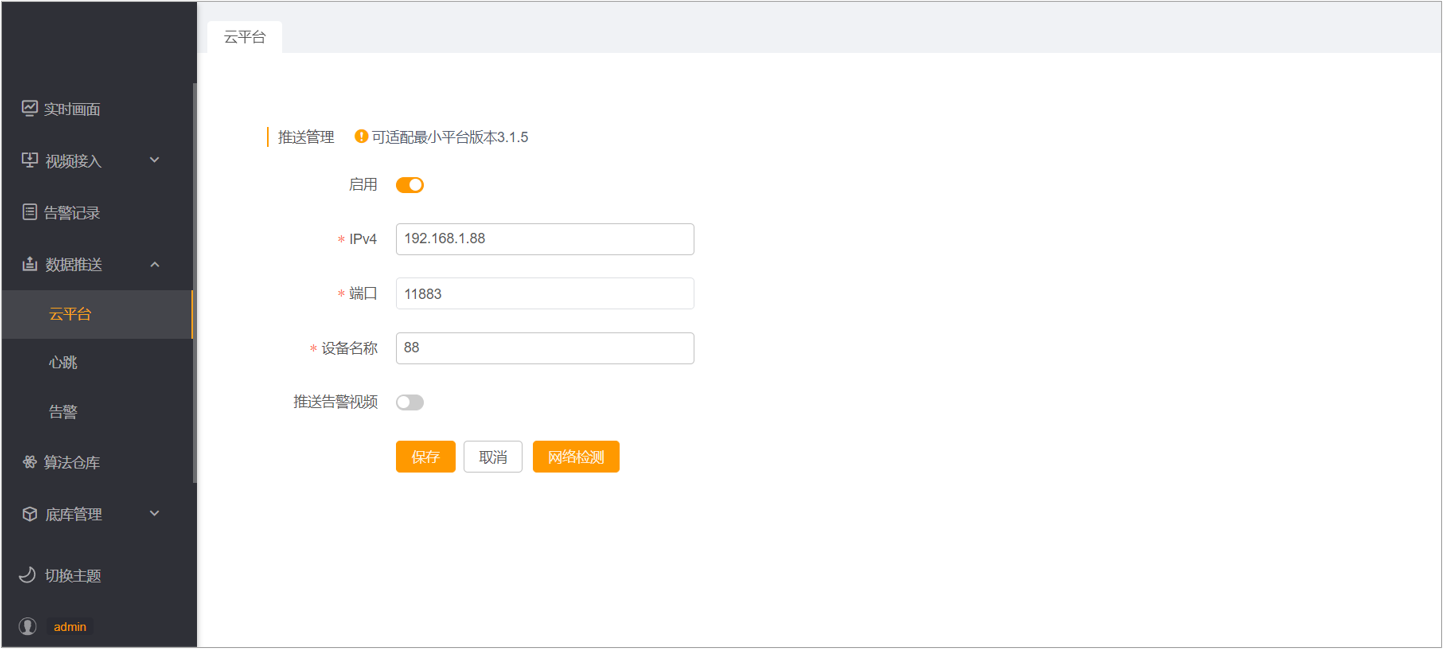
- 数据推送。在盒子【数据推送】-【云平台】中设置多模态大模型AI视频分析系统的推送地址。
- 创建复审任务。填写任务名称、提示词,选择复审算法,创建复审任务。
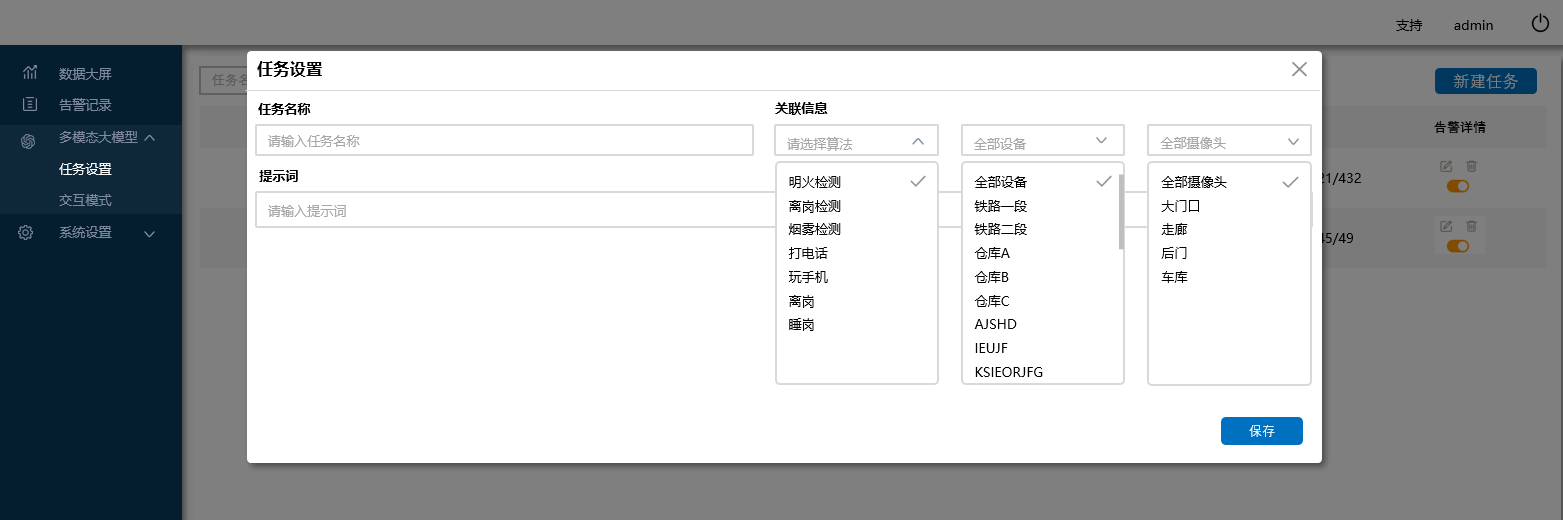
- 任务列表查看。查看正在复审的算法任务。

- 复审结果查看。查看大模型对每条告警记录的复审结果。
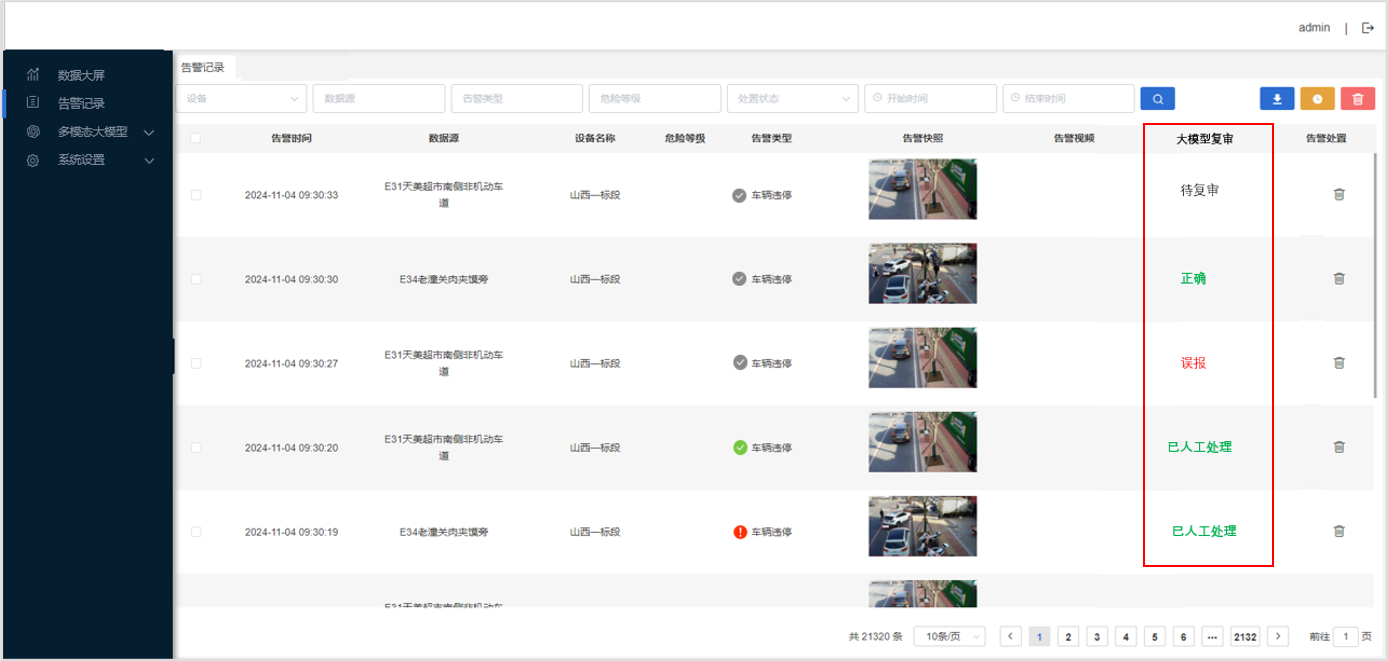
5、案例分析
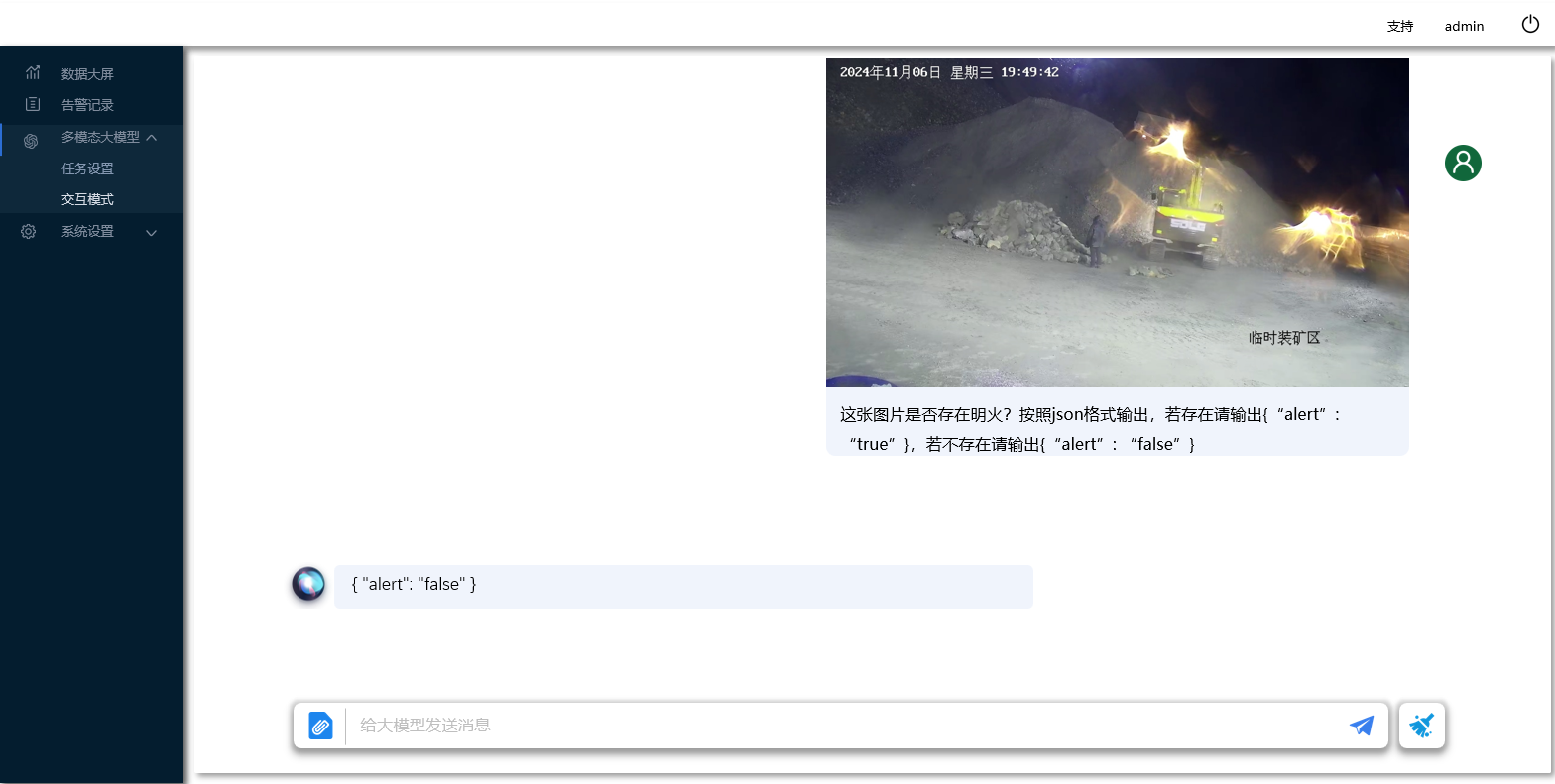
下图为明火检测大模型提示词&检测结果。由于现场灯光与明火类似,小模型造成误报。大模型可基于明火周围语义特征与明火形状特征作出决策。
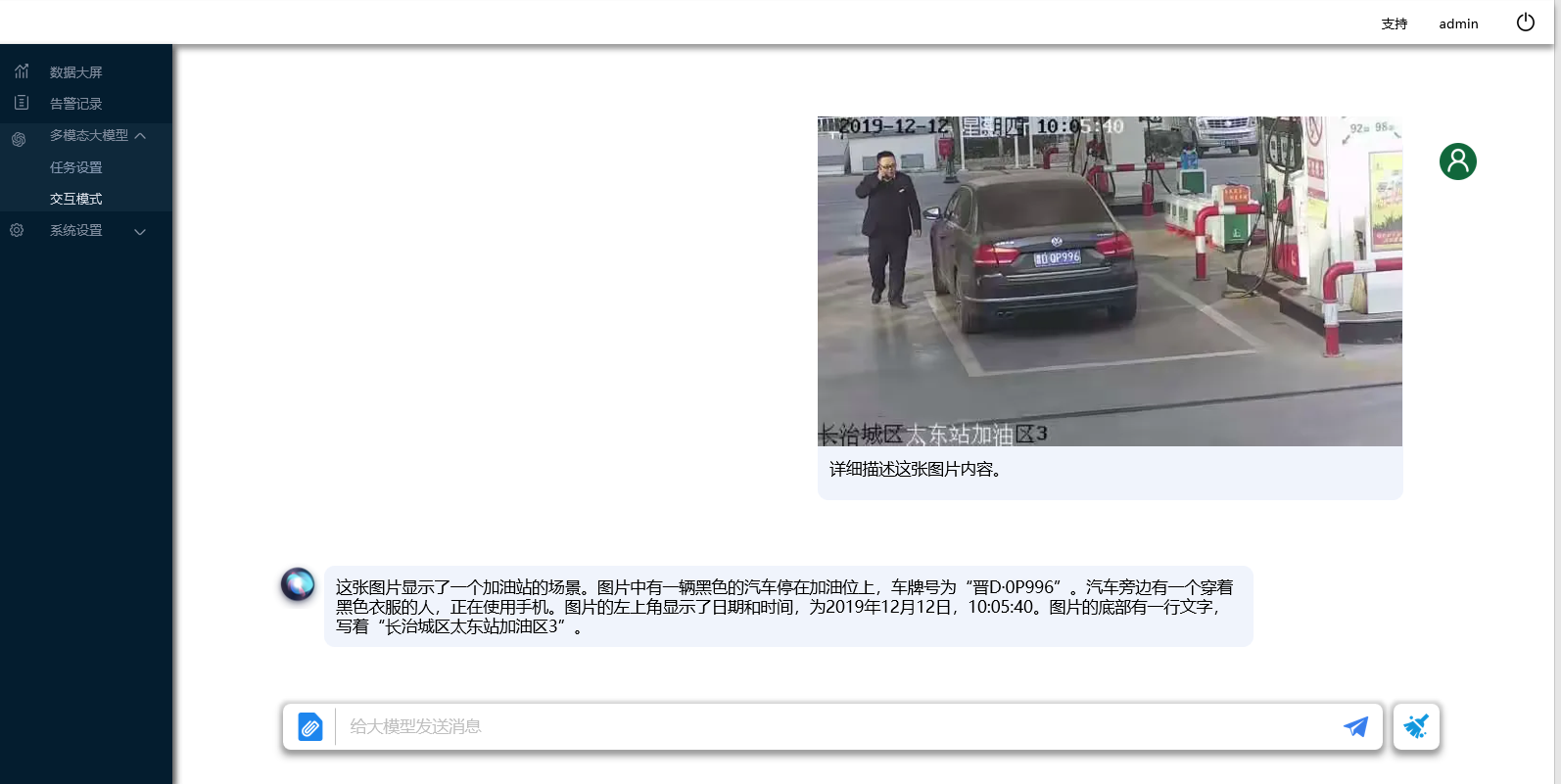
下图为结构化提取大模型提示词&检测结果。大模型可对图片人物、事件、时间等结构化数据进行准确提取。
6、产品价值
多模态大模型基于其独特的语义理解能力,解决小模型复杂场景语义识别精准度不足问题。产品优势如下。
- 二次复审,复杂语义识别精准度高。结构化标准场景识别准确率达99.8%,碎片化非标场景识别准确率达89.6%。对小模型识别结果误报过滤比达82.5%。
- 自定义算法,碎片化场景需求开发成本低。自定义提示词,快速生成算法技能。新算法开发成本降低91%。
总结: 大模型的出现给视频场景理解与分析带来了全新视角,其独特的高度语义理解能力与指令化交互方式可应对复杂场景复杂业务逻辑下的精准识别。智驱力在人工智能视频分析与多模态大模型领域深耕多年,基于丰富的工业场景数据与模型架构优化&微调能力,可快速应用复杂场景高精度识别需求。
Edited by pflying shan


回复